day01-6/11
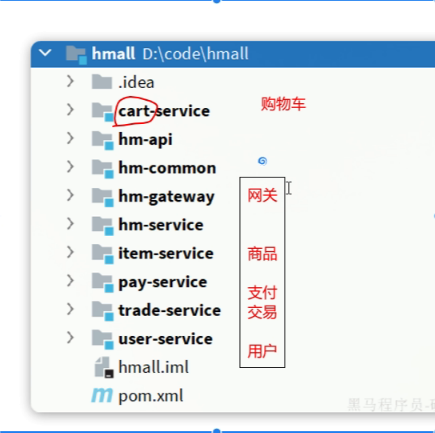
初始项目结构(单体)
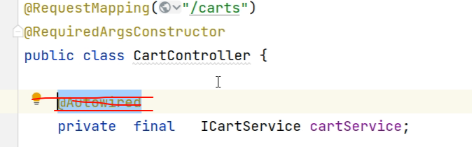
本项目中@Autowired被lombok的构造注解和final关键字代替。 优雅
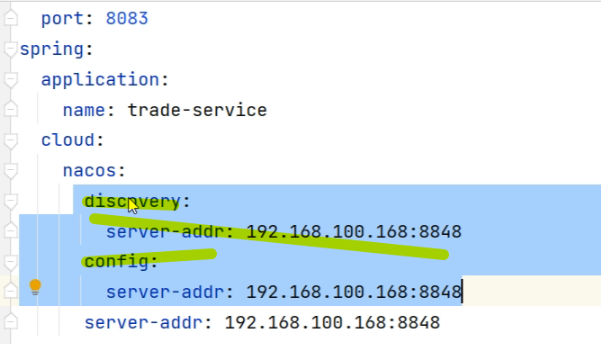
配置文件yml中disovery注册中心和config配置中心,ip一致时可以省略成以上写法
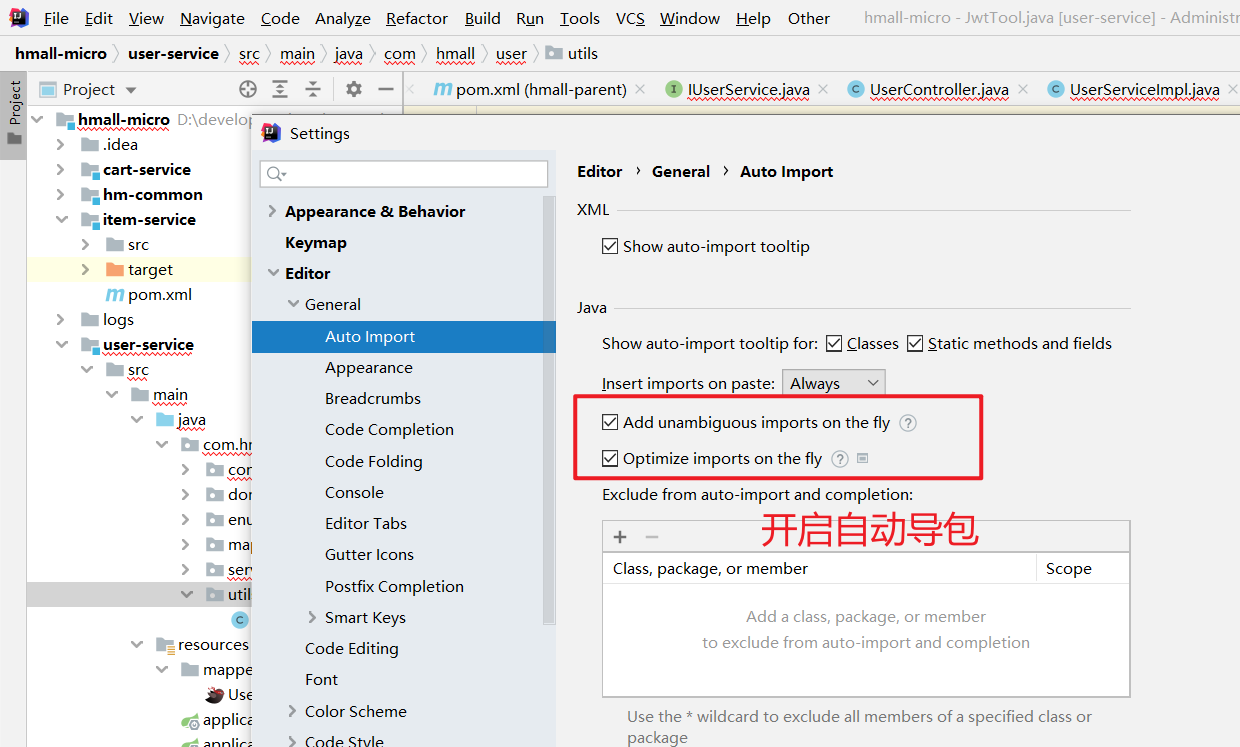
配置自动导包
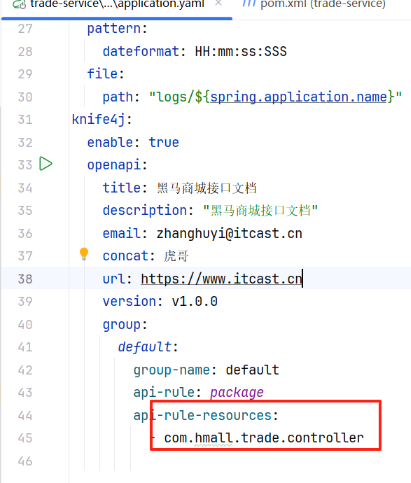
配置文件包名没改,导致注册假象,swagger无法显示菜单栏
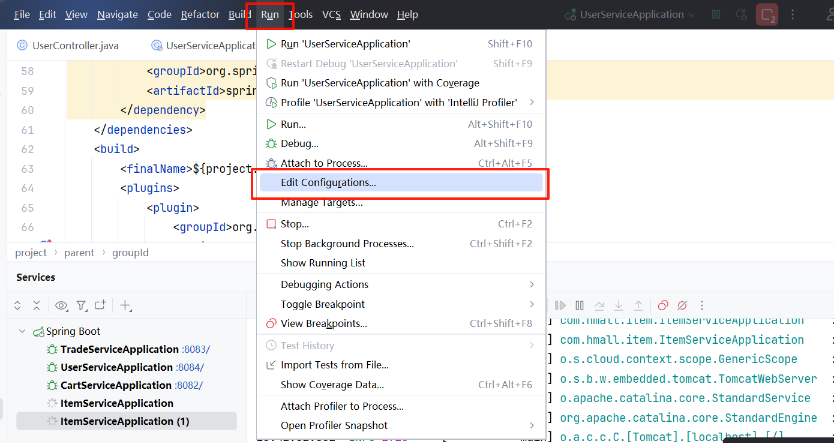
拆分模块代码的过程中,出现启动类错误的异常
运行的是com.hmall.UserApplication
而我的启动类是com.hmall.user.UserApplication,问题出在启动的不是一个地方,所以找不到。
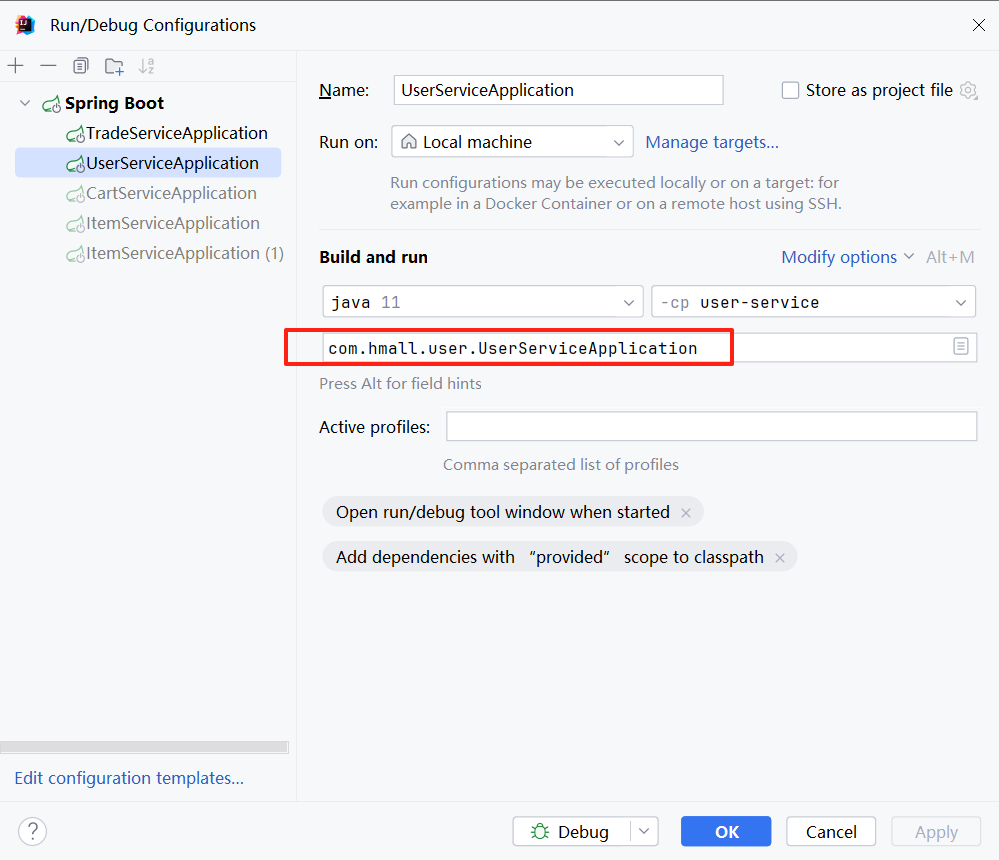
在这里,修改成功
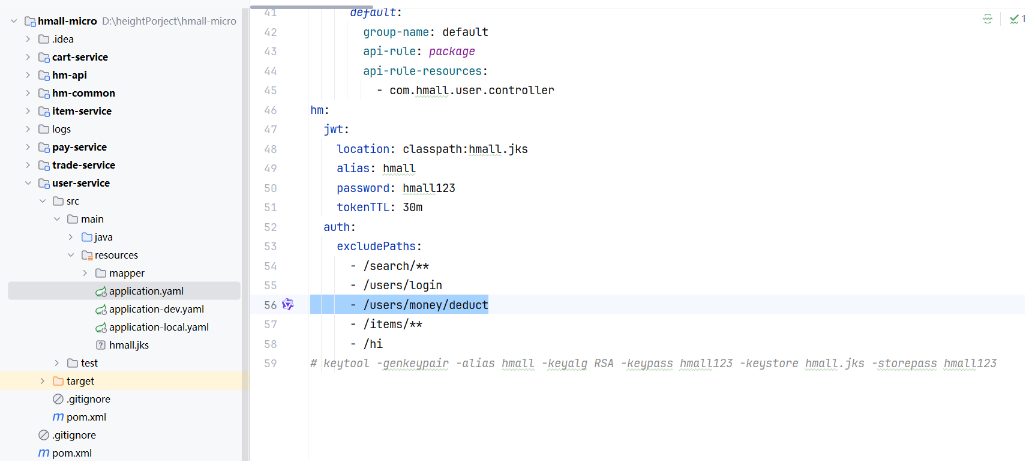
另外最后一个pay模块完成时候出现了一个bug,前端500后端报错只能用余额类型下单和未登录一起出现。
原因是拦截器拦截了扣除余额的方法,把该方法请求路径放开即可,如下配置:解决
总结6/12学习:
一、铺垫
1.微服务:
按功能拆分成多个小模块,可以相互远程调用(SpringCloud)
应对高并发、商城类大型项目
2.SpringCloud:
一些组件的集合
每个组件可以解决微服务架构中不同的问题。
3.SpringCloud和SpringBoot有什么关系?
用SpringCloud,必须用Springboot
他们俩的版本有关系,如SpringCloud的2021.0.X aka Jubilee 要使用 2.6或2.7的SpringBoot
二、拆分实践
单体项目拆分实践
1.首先确定Spring Cloud、Spring Boot版本,在父工程pom.xml中设定版本号。
2.每个微服务创建单独的数据库
3.每个微服务创建Spring Boot工程,继承父工程,并在application.yaml配置端口、服务名、
数据库连接池、日志、swagger、拦截器的拦截(!!!注意)等配置信息。
4.每个微服务工程的目标结构包括:
controller: web接口
service: 服务接口
domain: 模型类
mapper: 数据库mapper
思考:
什么时候需要拆分?
小公司先单体架构快速开发-业务跑通规模扩大-再拆分微服务
如何拆分?
高内聚、低耦合
纵向是按照业务功能分模块、横向是拆分通用业务,提高复用性
服务拆分后,一定会出现跨微服务业务,微服务之间如何进行远程调用(RPC)呢?
微服务被调用较多,为了应对更高的并发,进行多实例部署,服务者这么多实例,调用者如何知道每一个实例的地址?
使用阿里的组件Nacos(注册中心实现服务的治理):完成服务注册
引入依赖
配置Nacos地址
重启
负载均衡切换实例
OpenFeign(让远程调用像本地方法调用一样简单)
四要素,抽取Client接口
OpenFeign用SpringMVC的相关注解来声明4个参数,帮我们生成远程调用的代码,而无需我们手动再编写
6/13
小结
网关使用:
1.网关微服务
2.引入SpringCloudGate、NacosDiscovery依赖
网关依赖
Nodes 注册中心
负载均衡
3.新建启动类和ymal路由配置(配置是重点)
网络登录校验:
1.过滤器
13号其实学了就是一张图
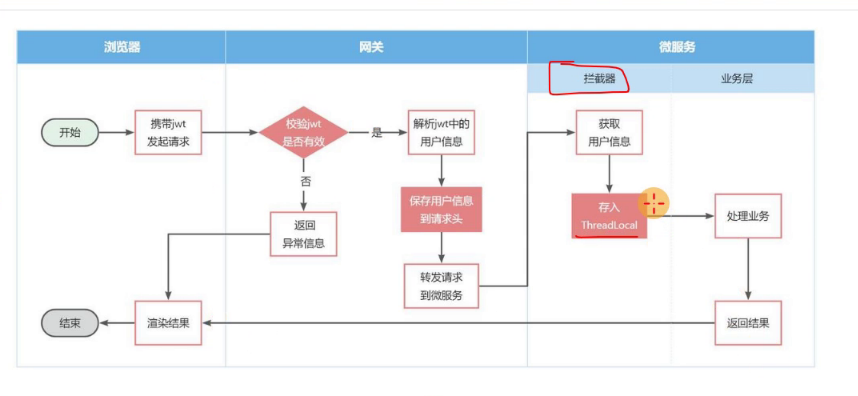
浏览器发的请求都会 发送到微服务
但是会先进入网关,干脆在网关(浏览器校验带回来的token是否有效)
token有效的话,在解析token里的用户信息,获取用户ID
获取到用户ID,放到请求头,再转到微服务,最终用户ID在微服务中用
微服务中统一获取用户ID(可以在每个Controller的每个方法中获取用户ID,不过有些麻烦,直接在每个微服务里搞个拦截器(这个拦截器可以接收网关传过来的用户信息,直接放到ThroadLocal中,其他微服务直接获取))
另外有个业务问题,Fogin直接传输的话,使用Fogin的两个方案解决即可
6/14
1、Nacos配置中心:将项目配置抽取放到Nacos配置中心中
作用:用的时候直接加载Nacos中的配置,不需要一个一个改了
2、抽取配置步骤
1.两个依赖
2.application.yaml: application.yaml中的配置全放到Nacos的配置中心 修改
3.application-dev.yaml: 抽取公共的放到application-dev.yaml中 修改
4.配置中心设置 服务名-service-dev.yaml,加载微服务配置和公共配置
3、配置文件的加载顺序
先加载Bootstrap配置
再加载application.yaml配置
最后nacos的:共享配置文件、扩展配置文件
加载完之后会有一个合并
6/16
MQ:高性能的异步通信组件 常用RabbitMQ(rabbit)、和RocketMQ(阿里)、Kafka(Apache)
作用:使用异步可以借用MQ而不再需要线程池,能解决(扩展性差、性能下降、级联失败)三个常遇见的问题
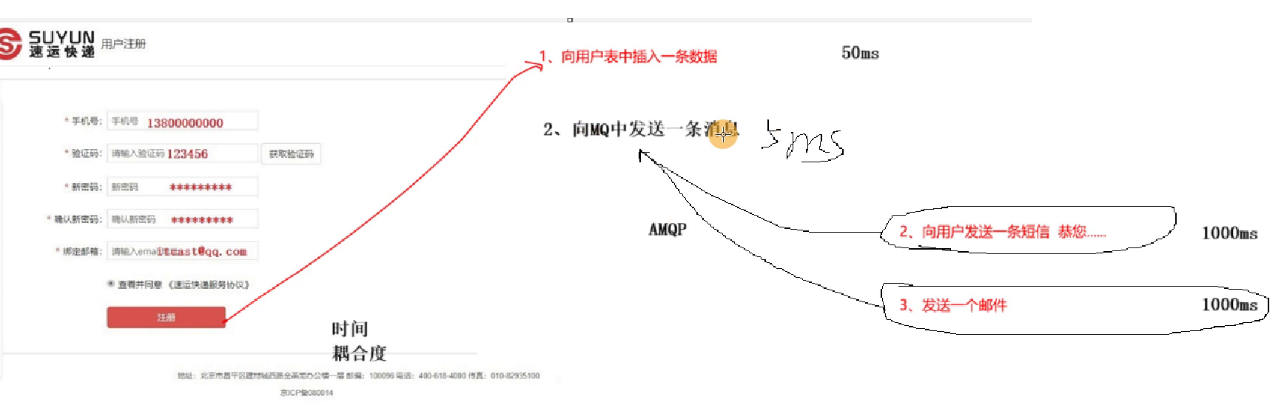
举例:向MQ中发送一条消息比向用户表中插入一条数据 速度更快
使用场景如下
1、MQ的相关架构和概念
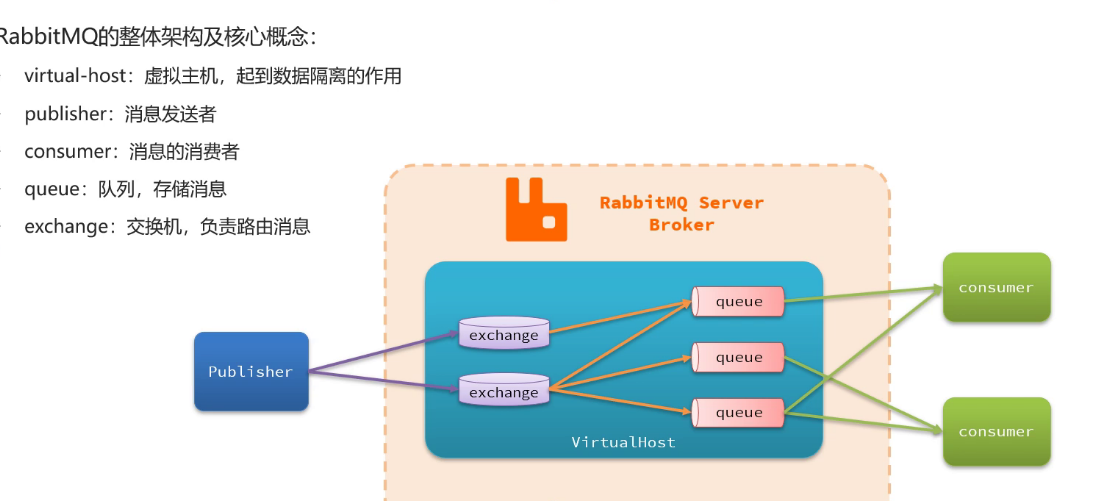
publisher(发送者)和 consumer(消费者)自己写代码
queue(队列):存储消息
exchange(交换机):转路由消息
vitualHost(虚拟主机): 数据消息隔离
总结下来就是,在MQ中的规律:1.交换机和路由之间得有个绑定关系 2.交换机不存消息
2、MQ的五个消息模型(用JAVA代码应用MQ)
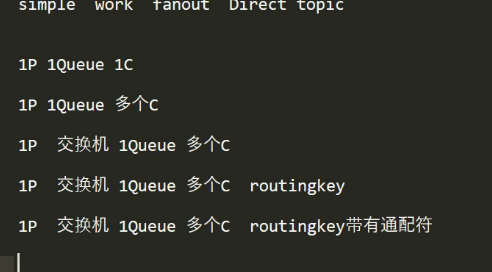
代码略,具体看MQ入门中代码
总结:(学了上面!!!)
点一:为什么用MQ总结一句话来说就是:异步解耦,流量削峰
异步解耦: 异步就是发完请求之后直接就回去了不需要等待,解耦就是使用MQ之后不同微服务之间即使出错了也不会有互相影响
流量削峰: 并发特别大的时候,可以解决高峰问题
点二:MQ五个消息模型
P(发送者) 向 Queue(MQ的队列)中发送消息 C(消费者)从MQ的队列中接收消息。
6/19
目前黑马商城有两个问题
第一个问题:索引失效 SELECT *FROM item WHERE NAME LIKE'%华为% LIKE条件查询时以%开头索引失效
第二个问题:内容多了导致搜不到结果没有分词
解决方案就是使用Elasticsearch(一个搜索框架),还有分词器IK
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
学前复习:
ELK技术栈,elasticsearch结合kibana、Logstash、Beats,是一整套技术栈,被叫做ELK。被广泛应用在日志数据分析、实时监控等领域。
单用elasticsearch就是做搜索使用
!!!记得修改IK分词器的lg配置格式
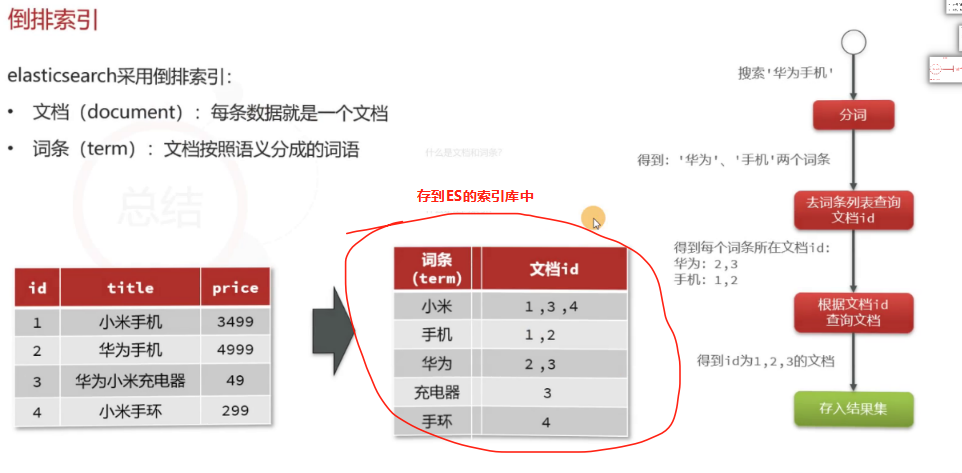
倒排索引的俩概念:
文档:每条数据
词条:对文档内容做分词,分词后的结果
索引(索引库):同类型的文档的集合
映射(mapping):索引l中文档的字段约束信息,类似表的结构约束
什么是倒排索引(创建和搜索):
1.对文档原始内容分词,对词条创建索引,并记录词条所在文档的id。
2.查询词条时先根据词条查询到文档原始id,而后根据文档id查询文档。
RESTAPI操作索引库
创建索引库不用Java代码,Java代码主要用来操作文档的
总结:
分词器的作用是什么?
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
总结:
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 修改索引库,添加字段:PUT /索引库名/_mapping
可以看到,对索引库的操作基本遵循的Restful的风格,因此API接口非常统一,方便记忆。
文档操作有哪些?
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档: 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }局部修改:POST /{索引库名}/_update/文档id { "doc": {字段}}
推荐阅读:








文章有(0)条网友点评